Zammad 7.0 On-Premise: Volle KI-Leistung, ohne dass Ihre Daten den Server verlassen
Ein praktischer Leitfaden zum Self-Hosting von Zammad 7.0 mit seinen neuen KI-Funktionen — behandelt Einrichtung, Infrastrukturkosten, LLM-Auswahl und wie Sie jedes Byte der Ticket-Daten auf Ihrer eigenen Hardware behalten.

Zammad 7.0 On-Premise: Volle KI-Leistung, ohne dass Ihre Daten den Server verlassen
Zammad 7.0 erschien am 4. März 2026 — und es ist ein großer Wurf. Zum ersten Mal bringt Zammad native KI-Funktionen mit: automatische Ticket-Kategorisierung, KI-gestützte Zusammenfassungen und einen Schreibassistenten, der direkt in die Agenten-Oberfläche integriert ist. Der Clou? Sie wählen das LLM. Sie können alles auf Ihren eigenen Servern betreiben. Keine Daten müssen Ihr Netzwerk verlassen.
Neu bei Zammad 7 KI? Lesen Sie unseren kompletten Leitfaden zu den Zammad 7 KI-Funktionen fur einen tiefen Einblick in Ticket-Zusammenfassungen, Schreibassistenten, KI-Agenten und Cloud-Anbieter-Optionen.
Dieser Beitrag führt durch das, was Zammad 7.0 bringt, wie man es mit Docker on-premise einrichtet, was es tatsächlich kostet, es zu hosten, und wie man sicherstellt, dass nicht ein einziges Ticket jemals eine externe API berührt, die Sie nicht kontrollieren.
Was ist neu in Zammad 7.0
KI-Agenten
Zammad hat jetzt KI-Agenten, die direkt in Trigger, Makros und Scheduler-Jobs eingebunden werden können. Sie übernehmen automatische Kategorisierung, Prioritätszuweisung und können sogar Ticket-Titel zur besseren Verständlichkeit umschreiben. Jede KI-Aktion wird im Ticket-Verlauf protokolliert — vollständige Prüfspur, keine Blackbox.
Wenn ein KI-Agent an einem Ticket arbeitet, sehen andere Agenten eine Live-Kollisionsanzeige in der UI. Keine versehentlichen Überschreibungen.
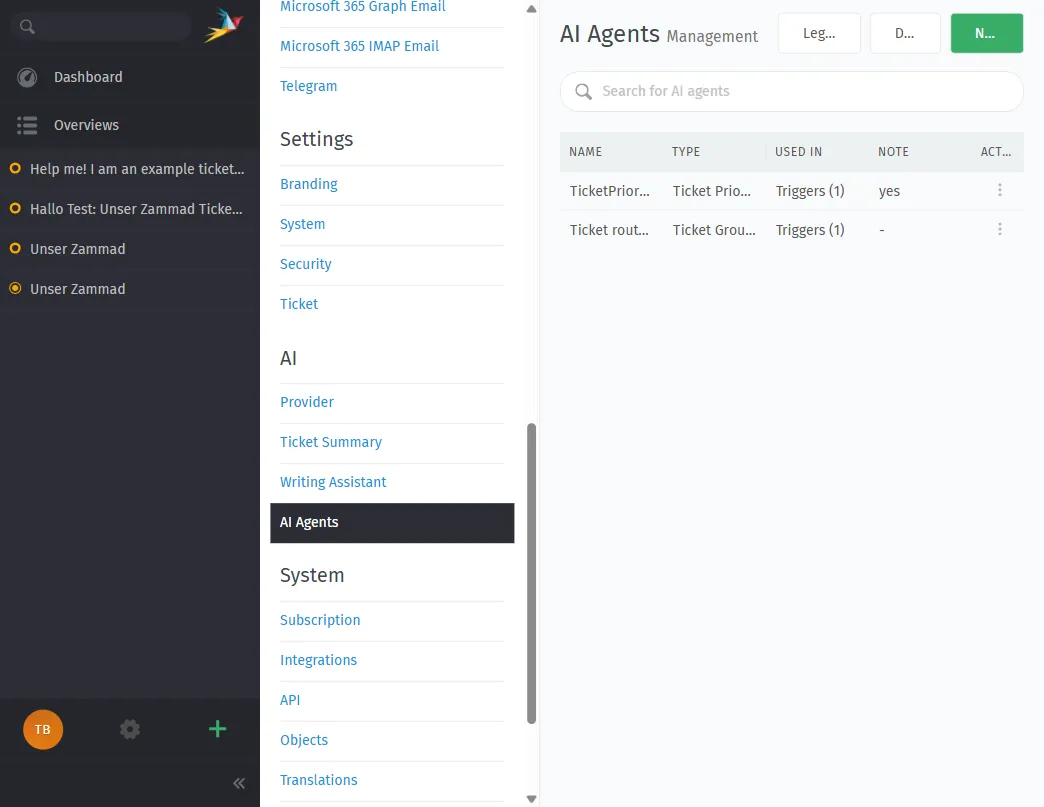
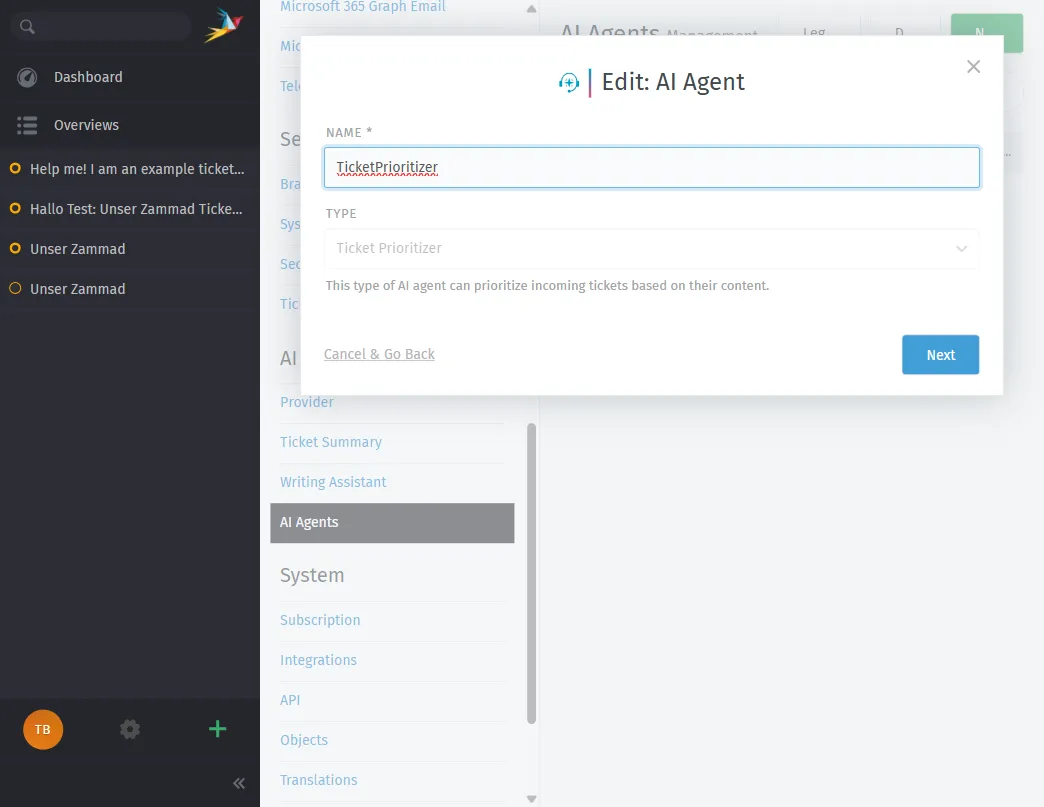
Hier ist der Konfigurationsdialog für einen KI-Agenten. Sie können aus vordefinierten Typen wie Ticket Prioritizer, Ticket Categorizer, Ticket Group Dispatcher, Ticket Title Rewriter wählen oder einen vollständig benutzerdefinierten Agenten erstellen:
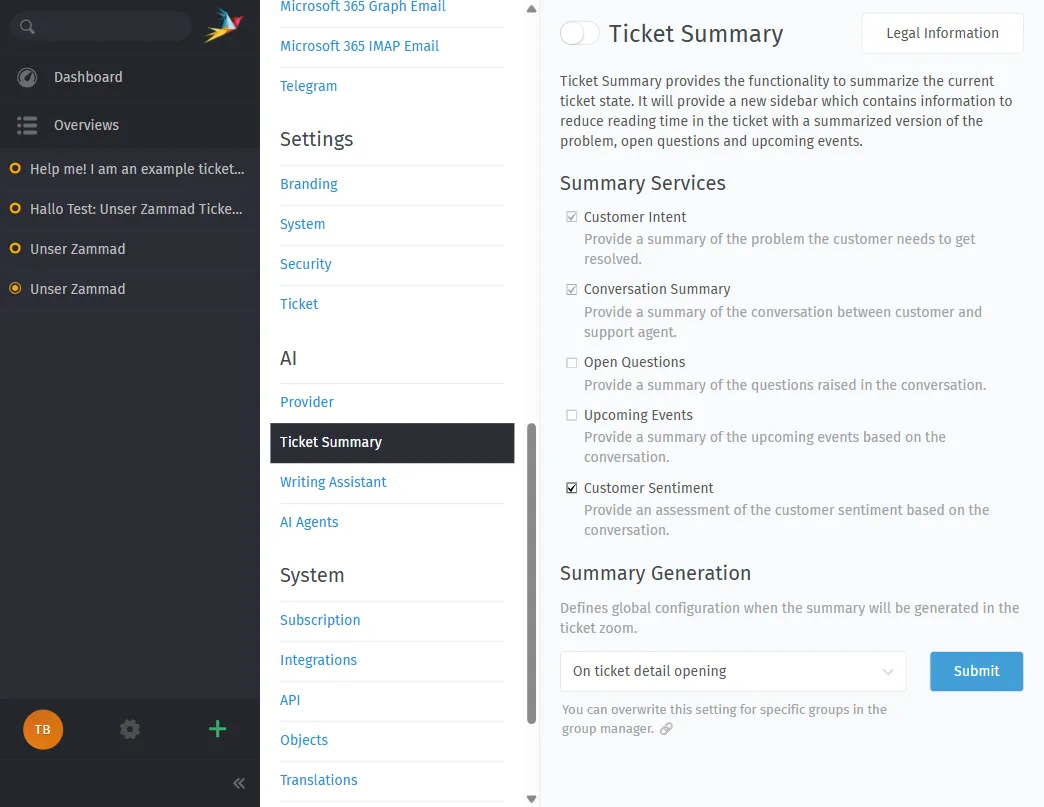
KI-Ticket-Zusammenfassung
Lange Ticket-Threads erhalten eine Ein-Klick-TL;DR. Die Zusammenfassung gliedert:
- Kundenabsicht — was der Kunde tatsächlich möchte
- Gesprächszusammenfassung — was besprochen wurde
- Offene Fragen — welche Informationen noch fehlen
- Bevorstehende Ereignisse — ausstehende Rückrufe, Fristen, Sendungen
- Kundenstimmung — kooperativ, neutral, frustriert
Dies ist ein enormer Zeitgewinn für Übergaben und Eskalationen.
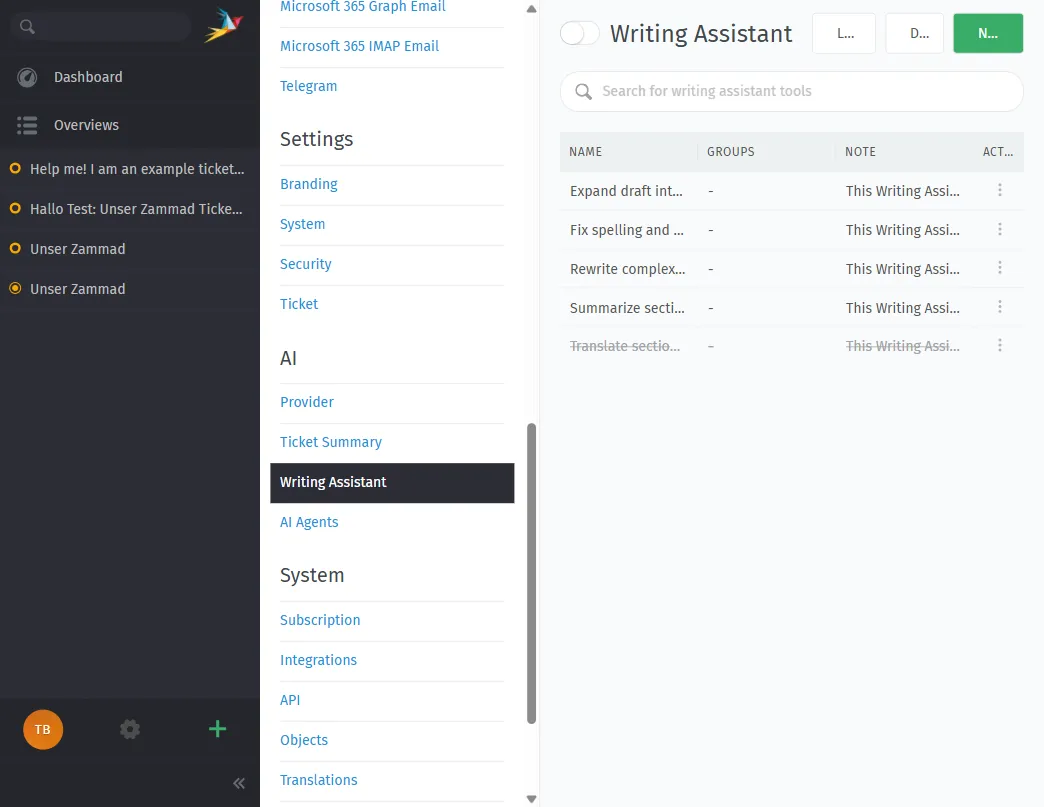
KI-Schreibassistent
Der Schreibassistent hilft Agenten, Antworten zu verfassen und zu verfeinern. Standardmäßig kann er:
- Rohentwürfe in ausgefeilte Absätze umwandeln
- Rechtschreibung und Grammatik korrigieren
- Komplexen Text umformulieren
- Lange Passagen zusammenfassen
- In andere Sprachen übersetzen
Sie können auch benutzerdefinierte Schreibwerkzeuge für branchenspezifischen Ton oder Formulierungen erstellen. Alle Vorschläge sind genau das — Vorschläge. Der Agent hat immer die endgültige Entscheidung.
Breaking Changes, die Sie kennen sollten
Vor dem Upgrade beachten Sie:
- MySQL-Unterstützung ist weg. Zammad 7.0 benötigt PostgreSQL. Wenn Sie noch MySQL verwenden, müssen Sie zuerst migrieren.
- Elasticsearch-Index-Neuerstellung erforderlich nach dem Update (neue ASCII-Folding-Unterstützung).
- nginx-Konfiguration muss aktualisiert werden — prüfen Sie den offiziellen Migrationsleitfaden.
- Slack-Integration entfernt — verwenden Sie stattdessen Webhooks.
- Twitter/X-Integration entfernt.
Der Aspekt der Datensouveränität
Hier ist der Grund, warum Zammad 7.0 on-premise wichtig ist: Sie erhalten KI-Funktionen ohne den üblichen Kompromiss, Ihre Daten an OpenAI, Anthropic oder Google zu senden.
Zammad 7.0 führt eine KI-API-Schicht ein, in der Sie konfigurieren, welches LLM verwendet werden soll. Das Admin-Panel lässt Sie wählen zwischen Zammad AI, OpenAI, Ollama, Anthropic, Azure AI, Mistral AI oder einem beliebigen benutzerdefinierten OpenAI-kompatiblen Endpunkt:
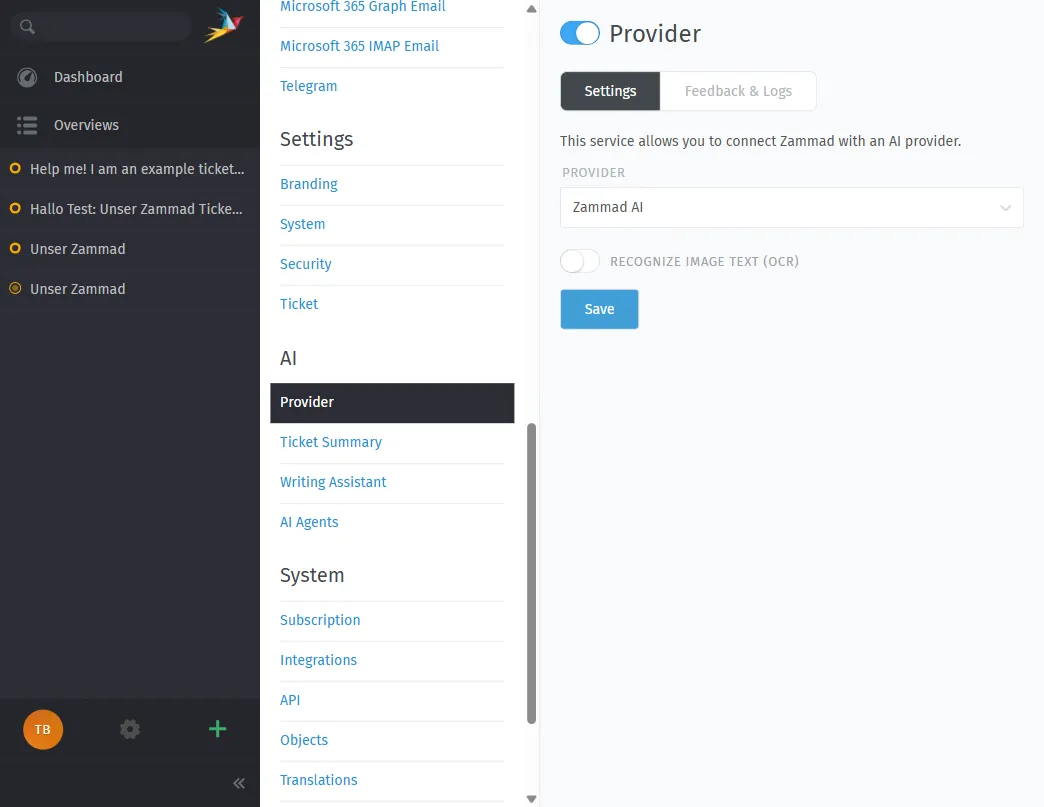
Ihre Optionen:
- Cloud-LLMs — OpenAI, Anthropic Claude, Google Gemini, Mistral AI (Daten verlassen Ihr Netzwerk)
- Self-gehostete Open-Source-Modelle — Meta Llama, Mistral oder jede OpenAI-kompatible API, die auf Ihrer eigenen Hardware läuft (Daten bleiben on-premise)
Für maximale Datenkontrolle ist Option 2 das, was Sie wollen. Führen Sie ein Open-Source-LLM wie Llama 3 oder Mistral über Ollama, vLLM oder LocalAI auf einem GPU-Server in Ihrem eigenen Rechenzentrum aus. Richten Sie Zammads KI-API-Konfiguration auf http://ihr-internes-llm:8080 und Sie sind fertig. Null Daten verlassen das Gebäude.
“Unternehmen sollten nicht vor die unmögliche Wahl gestellt werden, entweder KI-Technologie zu übernehmen oder ihre Daten zu schützen.” — Martin Edenhofer, Gründer & CEO, Zammad
Ausrichtung auf den EU-KI-Akt
Zammad hat seine KI-Funktionen explizit mit dem EU-KI-Akt im Blick entwickelt:
- Mensch in der Schleife — KI unterstützt, Menschen entscheiden
- Vollständige Prüfspur — jede KI-Aktion im Ticket-Verlauf protokolliert
- Open-Source-Codebasis — überprüfbar und transparent
- LLM-Auswahl — Sie kontrollieren, wo Daten verarbeitet werden
Wenn Sie in einer regulierten Branche tätig sind (Gesundheitswesen, Regierung, Finanzen, kritische Infrastruktur), ist dies wichtig.
Self-Hosting von Zammad 7.0 mit Docker
Systemanforderungen
Zammads offizielle Hardware-Anforderungen (aus ihrer Dokumentation):
Minimum (kleine Teams):
| Ressource | Spezifikation |
|---|---|
| CPU | 2 Kerne |
| RAM | 6 GB (+ 4 GB, wenn Elasticsearch auf demselben Server läuft) |
| Speicher | 50 GB SSD |
Empfohlen (bis zu 40 Agenten):
| Ressource | Spezifikation |
|---|---|
| CPU | 6 Kerne |
| RAM | 6 GB (+ 6 GB für Elasticsearch auf demselben Server) |
| Speicher | 100+ GB SSD |
Software-Stack:
- PostgreSQL (einzige unterstützte Datenbank seit 7.0)
- Elasticsearch (für Volltextsuche, dringend empfohlen)
- Redis oder Dateisystem-Caching
- Docker + Docker Compose (empfohlene Bereitstellungsmethode)
- nginx als Reverse Proxy
Docker Compose Setup
Zammad stellt einen offiziellen Docker Compose Stack bereit. Hier ist der schnelle Weg:
# Klonen Sie das offizielle Docker-Setup
git clone https://github.com/zammad/zammad-docker-compose.git
cd zammad-docker-compose
# .env-Datei überprüfen und anpassen
cp .env.dist .env
nano .env
# Stack starten
docker compose up -dDer Standard-Stack startet:
- Zammad-Anwendung (Rails + Hintergrund-Worker)
- PostgreSQL-Datenbank
- Elasticsearch für die Suche
- Redis für Caching
- Nginx als Reverse Proxy
Alles läuft in isolierten Containern auf Ihrem Server. Keine externen Abhängigkeiten, kein Phone-Home, keine Telemetrie.
Hinzufügen eines Self-gehosteten LLM
Welches Modell sollten Sie wählen? Nicht jedes Ollama-Modell funktioniert mit Zammad AI — manche brechen die benötigte strukturierte JSON-Ausgabe. Im Leitfaden bestes Ollama-Modell für Zammad AI finden Sie die wirklich funktionierenden Modelle, echte Geschwindigkeitswerte und VRAM-Dimensionierung.
Um KI-Funktionen vollständig on-premise zu halten, benötigen Sie einen lokalen LLM-Server. Die einfachste Option:
# Auf einem GPU-ausgestatteten Server (oder demselben Server, wenn er eine GPU hat)
docker run -d --gpus all \
-v ollama:/root/.ollama \
-p 11434:11434 \
--name ollama \
ollama/ollama
# Ein Modell herunterladen
docker exec -it ollama ollama pull llama3.1:8bKonfigurieren Sie dann Zammads KI-Einstellungen, um Ihren lokalen Endpunkt zu verwenden:
- Anbieter: OpenAI-kompatibel
- API-URL:
http://ihr-server:11434/v1 - Modell:
llama3.1:8b - API-Schlüssel: (leer lassen oder einen Dummy-Wert für lokales Ollama verwenden)
Jetzt laufen Ticket-Zusammenfassungen, KI-Agenten und der Schreibassistent alle über Ihr lokales Modell. Keine Daten verlassen Ihre Infrastruktur.
Was kostet es tatsächlich?
Lassen Sie uns die realen Kosten für den Betrieb von Zammad 7.0 on-premise aufschlüsseln.
1. Server-Hosting
Sie benötigen mindestens einen Server für Zammad und optional einen zweiten für das LLM, wenn Sie on-premise KI wollen.
Zammad-Server (Hetzner, OVH oder ähnliche europäische Anbieter):
| Setup | Specs | Monatliche Kosten |
|---|---|---|
| Minimum | 2 vCPU, 8 GB RAM, 80 GB SSD | ~€10–15/Monat |
| Empfohlen | 6 vCPU, 16 GB RAM, 200 GB SSD | ~€25–40/Monat |
| Produktion | 8 vCPU, 32 GB RAM, 500 GB NVMe | ~€50–80/Monat |
LLM-Server (nur bei vollständig on-premise KI):
| Setup | Specs | Monatliche Kosten |
|---|---|---|
| Budget-GPU | RTX 3090/4090 Dedicated Server | ~€80–150/Monat |
| Produktions-GPU | A10/A100 Cloud GPU (Hetzner, Lambda) | ~€150–400/Monat |
Wenn Sie bereits GPU-Hardware in Ihrem Rechenzentrum haben, sind die zusätzlichen Kosten nur Strom und Wartung.
Ohne lokales LLM können Sie immer noch Cloud-Anbieter wie Mistral AI (EU-basiert) nutzen, mit etwa €0,01–0,05 pro KI-Aufruf, was ein guter Mittelweg ist — EU-Datenresidenz, Pay-per-Use, keine GPU-Investition.
2. Zammad-Software
Zammad selbst ist Open Source und kostenlos. Die AGPL-Lizenz bedeutet, dass Sie es on-premise betreiben können, ohne Zammad einen Cent zu zahlen.
Wenn Sie jedoch offiziellen Support von Zammad GmbH wünschen:
| Plan | Was Sie erhalten | Preis |
|---|---|---|
| Business | E-Mail-Support, 8×5 CET, 6h Antwortzeit, 15 Anfragen/Jahr | Kontaktieren Sie den Vertrieb |
| Enterprise | E-Mail + Telefon, 8×10 CET, 4h Antwortzeit, 45 Anfragen/Jahr | Kontaktieren Sie den Vertrieb |
| Corporation | E-Mail + Telefon, 8×12 CET, 2h Antwortzeit, 95 Anfragen/Jahr, Patch-Updates | Kontaktieren Sie den Vertrieb |
Für gehostetes/Cloud-Zammad beginnen die Pläne bei €7/Agent/Monat (Starter) bis zum Plus-Plan für unbegrenzte Agenten. Da wir aber über On-Premise sprechen — die Software selbst ist kostenlos.
3. Betriebskosten
Vergessen Sie nicht die versteckten Kosten des Self-Hostings:
- Backups — Automatisierte PostgreSQL + Elasticsearch-Snapshots. ~€5–10/Monat für Off-Site-Backup-Speicher.
- SSL-Zertifikate — Kostenlos mit Let’s Encrypt.
- Monitoring — Uptime-Checks, Festplattenalarme, Container-Health. Kostenlos mit Tools wie Uptime Kuma oder Netdata.
- Updates — Sie sind verantwortlich für das Einspielen von Zammad-Updates, Sicherheitspatches und OS-Updates. Planen Sie 2–4 Stunden pro Monat für einen Sysadmin ein.
- DNS + Domain — ~€10–15/Jahr.
Gesamtkostenschätzung
| Szenario | Monatliche Kosten |
|---|---|
| Kleines Team (5 Agenten), keine lokale KI | €15–25/Monat |
| Mittleres Team (20 Agenten), Cloud-LLM (Mistral) | €40–60/Monat + KI-Nutzung |
| Großes Team (40+ Agenten), vollständig on-premise KI | €130–250/Monat |
Vergleichen Sie dies mit Zammads gehosteten Plänen, bei denen 20 Agenten im Professional-Plan €14 × 20 = €280/Monat kosten würden — und Sie erhalten immer noch nicht das gleiche Maß an Datenkontrolle.
Der komplette On-Premise-Datenfluss
Hier ist, was passiert, wenn ein Ticket in einem vollständig on-premise Zammad 7.0-Setup eingeht:
- Kunde sendet E-Mail → Ihr Mailserver empfängt sie
- Zammad holt die E-Mail ab → gespeichert in PostgreSQL auf Ihrem Server
- Trigger wird ausgelöst → ruft einen KI-Agenten zur Kategorisierung auf
- KI-Agent sendet Ticket-Text → an Ihr lokales LLM (gleiches Netzwerk)
- LLM gibt Klassifizierung zurück → Zammad aktualisiert das Ticket
- Agent öffnet Ticket → sieht KI-Zusammenfassung, nutzt Schreibassistent
- Alle KI-Aufrufe → erreichen Ihre lokale Ollama/vLLM-Instanz
Zu keinem Zeitpunkt verlassen Daten Ihr Netzwerk. Die gesamte Kette — E-Mail-Erfassung, Datenbankspeicherung, KI-Inferenz, Agenten-Interaktion — läuft auf Hardware, die Sie kontrollieren.
Kombination von Zammad 7.0 mit Open Ticket AI
Die eingebauten KI-Funktionen von Zammad 7.0 decken Zusammenfassungen, Schreibassistenz und grundlegende Kategorisierung ab. Aber wenn Sie benutzerdefinierte, trainierte Klassifizierungsmodelle benötigen, die aus Ihren spezifischen Ticket-Daten lernen — da kommt Open Ticket AI ins Spiel.
Open Ticket AI trainiert ein benutzerdefiniertes Modell pro Kunde aus Ihren Warteschlangen-Metadaten (QueueSpec). Das Modell läuft on-premise via Docker, verbindet sich mit Zammad über das OTAI Zammad Plugin und liefert eine Klassifizierungsgenauigkeit, die generische LLMs für spezialisierte Domänen nicht erreichen können.
Die beiden Systeme ergänzen sich:
- Zammad 7.0 KI → Zusammenfassungen, Schreibassistenz, allgemeine Kategorisierung
- Open Ticket AI → spezialisierte, hochgenaue Klassifizierung, die auf Ihren Daten trainiert wurde
Beide laufen on-premise. Beide halten Ihre Daten dort, wo sie hingehören.
Erste Schritte
- Server bereitstellen — Hetzner, OVH oder Ihr eigenes Rechenzentrum. 4+ vCPU, 16 GB RAM Minimum.
- Zammad mit Docker Compose bereitstellen — folgen Sie dem offiziellen Docker-Leitfaden.
- PostgreSQL-Backups einrichten —
pg_dumpals Cron-Job, Off-Site gespeichert. - Ollama installieren für ein lokales LLM, wenn Sie vollständig on-premise KI wollen.
- Zammads KI-Einstellungen konfigurieren — auf Ihren lokalen LLM-Endpunkt zeigen.
- SSL einrichten mit Let’s Encrypt und einem Reverse Proxy.
- Erwägen Sie Open Ticket AI für benutzerdefinierte Klassifizierungsmodelle.
Ihr Helpdesk. Ihre Daten. Ihre KI. Zu Ihren Bedingungen.