KI-Ticket-Klassifizierung ohne historische Ticketdaten: Training mit QueueSpec
Wie Datenschutz-first-Teams KI-Ticket-Klassifizierung mit QueueSpec-Metadaten trainieren, statt historische Ticketdaten in die Cloud zu senden.

KI-Ticket-Klassifizierung ohne historische Ticketdaten ist besonders relevant für Teams, die Support-Automatisierung wollen, aber keine produktiven Ticketinhalte in externe Trainingspipelines geben dürfen. In vielen Service Desks enthalten Tickets personenbezogene Daten, interne Systeme, Verträge, Sicherheitsvorfälle oder sensible Kundenkommunikation.
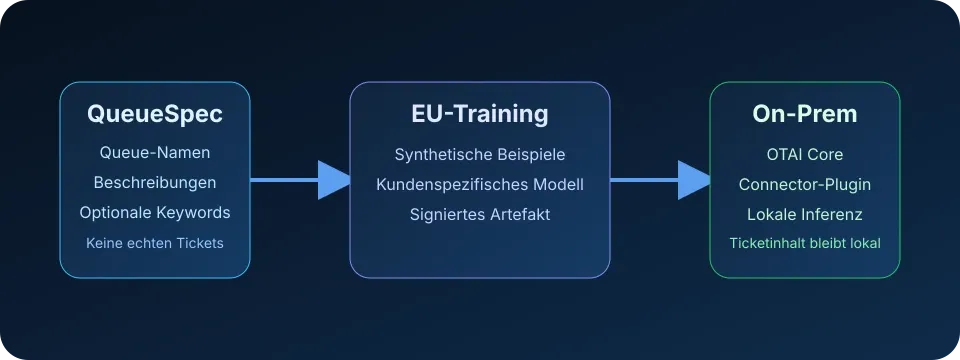
OTAI löst diese Spannung mit einem anderen Trainingsansatz: Das Modell wird aus einer QueueSpec trainiert, also aus strukturierten Metadaten über Warteschlangen, Gruppen, Tags oder andere erlaubte Zielwerte. Produktive Ticketinhalte bleiben während der Inferenz on-premise in der Kundenumgebung.
Warum historische Ticketdaten ein Beschaffungsproblem sind
Klassische KI-Projekte für Ticket-Routing starten oft mit der Frage: “Können Sie uns 10.000 gelabelte Tickets exportieren?”
Für viele Organisationen ist genau das der falsche Startpunkt:
- Der Export enthält personenbezogene Daten und vertrauliche Vorgänge.
- Daten müssen bereinigt, pseudonymisiert oder freigegeben werden.
- Historische Tickets spiegeln oft veraltete Routing-Regeln wider.
- Gelabelte Daten sind uneinheitlich, weil Agents in der Vergangenheit unterschiedlich gearbeitet haben.
- Datenschutz, Betriebsrat, Informationssicherheit und Fachbereich müssen zustimmen.
Selbst wenn der Export erlaubt ist, kann das Projekt dadurch in Governance-Arbeit stecken bleiben, bevor überhaupt ein Modell bewertet wurde.
Was eine QueueSpec enthält
Eine QueueSpec beschreibt, welche Zielwerte das Modell vorhersagen soll. Das können Warteschlangen, Gruppen, Prioritäten, Produkte, Kategorien oder andere begrenzte Felder sein.
Eine minimale QueueSpec enthält:
| Feld | Zweck |
|---|---|
queue_id | Stabile technische Kennung |
queue_name | Sichtbarer Name im Ticketsystem |
description | Zwei bis fünf klare Sätze darüber, welche Tickets hierher gehören |
Optional können Teams weitere Metadaten ergänzen:
- einzuschließende oder auszuschließende Keywords
- selbst geschriebene Beispiel-Betreffzeilen
- Sprache pro Queue
- Regeln wie “genau eine Queue” oder “maximal eine Priorität”
Wichtig ist: Diese Beispiele werden geschrieben, nicht aus echten Tickets exportiert.
Wie OTAI daraus ein Modell trainiert
Der OTAI-Ansatz trennt Training und produktive Inferenz:
- QueueSpec erstellen: Das Team beschreibt die Zielwerte in geschäftlicher Sprache.
- Training in der EU: Der Trainingsservice verarbeitet die QueueSpec-Metadaten und erzeugt synthetische Trainingsdaten.
- Modellartefakt ausliefern: OTAI stellt ein signiertes kundenspezifisches Modellartefakt bereit.
- On-premise deployen: Das Modell läuft in OTAI Core per Docker in der Kundenumgebung.
- Tickets lokal klassifizieren: Connectoren lesen neue Tickets lokal, führen Inferenz aus und schreiben strukturierte Vorhersagen zurück.
Dieser Ablauf passt zur OTAI-Produktstrategie: Training wird gemanagt, Inferenz läuft on-premise, und produktive Ticketdaten müssen für das Training nicht bereitgestellt werden.
QueueSpec-Training vs. Training auf historischen Tickets
| Kriterium | QueueSpec-Training | Training auf historischen Tickets |
|---|---|---|
| Produktive Ticketinhalte im Training | Nicht erforderlich | Typischerweise erforderlich |
| Datenschutzprüfung | Fokussiert auf Metadaten | Oft umfangreicher Datenexport |
| Startpunkt | Gewünschtes Routing-Zielbild | Historisch gewachsenes Routing |
| Datenqualität | Hängt von klaren Beschreibungen ab | Hängt von alten Labels ab |
| Wartbarkeit | QueueSpec kann bei Prozessänderungen aktualisiert werden | Neue Exporte und Bereinigung nötig |
Historische Tickets können später für Evaluation, Drift-Analysen oder On-premise Monitoring nützlich sein. Sie müssen aber nicht der erste Schritt für ein produktnahes Klassifizierungsprojekt sein.
Wann dieser Ansatz besonders gut passt
QueueSpec-basiertes Training ist stark, wenn:
- Sie klare Warteschlangen, Gruppen oder Kategorien haben.
- Tickets in Zammad, OTOBO, Znuny, GLPI oder ähnlichen Systemen strukturiert geroutet werden.
- Datenschutz und Infrastrukturkontrolle kaufentscheidend sind.
- historische Daten schwer zu exportieren oder rechtlich sensibel sind.
- Sie ein kundenspezifisches Routing-Modell statt einer globalen Taxonomie wollen.
Der Ansatz ist weniger passend, wenn die Zielwerte unklar sind oder das Team noch nicht weiß, wie Tickets überhaupt geroutet werden sollen. Dann sollte zuerst das Service-Modell bereinigt werden.
Was Teams vor dem Training vorbereiten sollten
Eine gute QueueSpec ist kein Datenexport. Sie ist ein präzises Modell der gewünschten Service-Logik.
Vor dem Training lohnt sich daher ein kurzer Review:
- Doppelte Queues entfernen: Wenn zwei Queues fast identisch sind, wird auch das Modell sie schwer trennen.
- Beschreibungen konkret schreiben: Jede Queue braucht klare Einschluss- und Ausschlusskriterien.
- Fallback definieren: Unklare Tickets sollten in eine Triage- oder Review-Queue gehen.
- Automatisierungsgrad festlegen: Manche Teams starten mit Vorschlägen, andere lassen sichere Vorhersagen direkt setzen.
- Bestehende Regeln berücksichtigen: Klassische Trigger, Makros und SLA-Regeln bleiben relevant.
Wie das in Ticketsysteme passt
OTAI ist als on-premise Automatisierungsschicht gedacht. Der Runtime Core läuft in der Kundenumgebung, Connectoren integrieren sich in das jeweilige Ticketsystem, und das Modell sagt strukturierte Werte voraus.
Für konkrete Plattformen gibt es passende Einführungen:
- OTAI für Zammad für Gruppenzuweisung, Priorität und Objektattribute
- OTAI für OTOBO für Queue-Routing und dynamische Felder
- OTAI für Znuny für Queue-, Prioritäts- und Typklassifizierung
Wenn Sie noch zwischen Systemen vergleichen, lesen Sie auch den Überblick zu Open-Source-AI-Ticketsystemen.
Fazit
KI-Ticket-Klassifizierung muss nicht mit einem Export sensibler historischer Tickets beginnen. Für viele Datenschutz-first-Teams ist eine QueueSpec der bessere Startpunkt: Sie beschreibt, wie Tickets künftig geroutet werden sollen, ohne produktive Ticketinhalte in die Trainingspipeline zu geben.
OTAI nutzt genau dieses Muster: kundenspezifisches Training aus QueueSpec-Metadaten, ein auslieferbares Modellartefakt und on-premise Inferenz neben dem Ticketsystem. So wird Ticket-Automatisierung möglich, ohne die Datenschutzgeschichte des Projekts unnötig schwer zu machen.